Introducción a SQL#
Introducción#
SQL es el lenguaje más popular para administrar y recuperar información de sistemas de bases de datos relacionales. Originalmente basado en el álgebra relacional y en el cálculo relacional de tuplas, SQL consta de muchos tipos de sentencias, que pueden ser clasificadas informalmente como sublenguajes, incluyendo un lenguaje de definición de datos, un lenguaje de manipulación de datos, un lenguaje de consulta de datos y un lenguaje de control de datos.
Historia#
IBM desarrolló la versión original de SQL, originalmente llamada SEQUEL (Structured English QUEry Language), como parte del proyecto System R a principios de la década de 1970. Algunos años después, SEQUEL cambió su nombre a SQL (Structured Query Language o Lenguaje de Consulta Estructurada) y se consolidó como el lenguaje estándar de bases de datos relacionales.
SQL ofreció dos ventajas principales sobre los antiguos mecanismos de lectura y escritura de datos. En primer lugar, introdujo la posibilidad de acceder a múltiples registros con un único comando. En segundo lugar, eliminó la necesidad de especificar cómo acceder a un registro, ya sea que cuente o no con un índice.
Al ser un lenguaje de programación declarativo, SQL le permite al programador especificar qué desea lograr sin tener que especificar cómo hacerlo, dejando que el lenguaje determine cómo obtener el resultado deseado. Sin embargo, SQL también incluye algunos elementos de programación procedimental.
SQL pasó a ser un estándar del Instituto Nacional Estadounidense de Estándares (ANSI) en 1986 y de la Organización Internacional de Normalización (ISO) en 1987. Esta primera versión es conocida como SQL-86 o SQL-1. En 1992 se publicó una revisión ampliada y revisada del estándar, llamada SQL-92 o SQL-2. El soporte a SQL-92 por parte de las implementaciones comerciales es muy amplio. El estándar ha sido revisado varias veces más para incluir características adicionales. La revisión más reciente es SQL:2023 y fue adoptada en junio 2023. A pesar de su estandarización, la mayoría de las implementaciones de SQL no son completamente portables entre sistemas administradores de bases de datos.
Sublenguajes#
Como se mencionó, SQL puede dividirse en varios lenguajes:
Lenguaje de definición de datos (DDL, por sus siglas en inglés). Proporciona comandos para crear, modificar y borrar objetos de una base de datos tales como tablas, índices y usuarios, entre otros. También para especificar restricciones de integridad (ej. llaves primarias, llaves foráneas, manejo de valores nulos).
Lenguaje de manipulación de datos (DML, por sus siglas en inglés). Permite insertar, modificar y borrar datos.
Lenguaje de consulta de datos (DQL, por sus siglas en inglés). Permite consultar la información de una base de datos.
Lenguaje de control de datos (DCL, por sus siglas en inglés). Contiene comandos para controlar el acceso a los datos. Por ejemplo, para otorgar o revocar permisos a los usuarios para insertar, modificar o borrar registros en tablas determinadas.
Lenguaje de control de transacciones (TCL, por sus siglas en inglés). Una transacción es una secuencia de una o más instrucciones SQL que se ejecutan como una única unidad de trabajo. Esto significa que o bien todas las instrucciones se ejecutan con éxito, o si alguna de ellas falla, ninguna de las instrucciones afecta a la base de datos. Esta propiedad es esencial para mantener la integridad y consistencia de la base de datos.
Sentencias y cláusulas#
SQL se compone de una variedad de sentencias y cláusulas que permiten realizar tareas como consultar datos, insertar registros, actualizar registros y definir estructuras de datos, entre otras.
Las sentencias son los comandos que se ejecutan para realizar una tarea específica en la base de datos. Las cláusulas son componentes de las sentencias que proporcionan detalles adicionales sobre cómo deben ejecutarse.
El siguiente es un ejemplo de la sentencia SELECT y sus cláusulas FROM, WHERE y ORDER BY.
-- Ejemplo de setencia SELECT y sus cláusulas FROM, WHERE y ORDER BY
SELECT name, tot_cred --columnas
FROM student --tabla
WHERE dept_name = 'Informática' AND tot_cred >= 50 --condición lógica
ORDER BY tot_cred DESC -- ordenamiento;
La sentencia SELECT del ejemplo anterior implementa una consulta que retorna los datos contenidos en las columnas name y tot_cred de una tabla. La función de cada una de las cláusulas se explica seguidamente:
La cláusula
FROMindica que la tabla que se va a consultar esstudent.La cláusula
WHEREespecifica una condición lógica: el departamento (dept_name) al que pertencen los estudiantes es “Informática” y su total de créditos (tot_cred) debe ser mayor o igual a 50.La cláusula
ORDER BYespecifica que los registros de salida de la consulta deben estar ordenados de mayor a menor (DESC) según la columnatot_desc.
Recomendaciones de estilo#
Las siguientes son algunas recomendaciones de estilo para la escritura de sentencias SQL.
Las palabras reservadas de SQL pueden escribirse en mayúsculas o minúsculas. Se recomienda escribirlas en mayúscula (ej.
SELECT,FROM,WHERE) para mejorar su legibilidad y seguir algunas convenciones.Si la sentencia es muy larga y no cabe en una sola línea, se recomienda dividirla en varias líneas (ej. una línea por cláusula).
Las sentencias SQL pueden finalizarse con punto y coma (
;). Es opcional, pero sí se utilizará en este curso para señalar claramente el final de cada sentencia y mejorar la legibilidad de scripts con varias sentencias.Se recomienda también el uso abundante de comentarios en las sentencias. Estos inician con dos guiones seguidos (
--) y pueden ocupar toda una línea o el final de una línea.
En este capítulo, se presentan las principales sentencias de SQL DDL, SQL DML y SQL DQL, con algunos ejemplos relacionados con la base de datos university, introducida en el capítulo anterior. Para más detalles sobre SQL y su sintaxis, se recomienda consultar Database System Concepts (Chapter 3), Database System Concepts (Chapter 4) y W3Schools - SQL Tutorial. Se recomienda también ejcutar las sentencias SQL en una base de datos real.
SQL DDL - Definición de datos#
SQL DDL permite definir, para una tabla, aspectos como su esquema, tipos de datos de los atributos y restricciones de integridad. También índices, información de seguridad y estructura física de almacenamiento en el disco.
Tipos de datos básicos#
El estándar SQL admiite varios tipos de datos, incluyendo [SKS19]:
char(n), character(n): cadena de caracteres de longitud fija n especificada por el usuario.
varchar(n), character varying(n): cadena de caracteres de longitud variable de tamaño máximo n especificado por el usuario.
int, integer: número entero de tamaño máximo dependiente de la arquitectura de la computadora.
smallint: número entero pequeño de tamaño máximo dependiente de la arquitectura de la computadora.
numeric(p,d): número de punto fijo1 con precisión especificada por el usuario. El número consta de p dígitos (más un signo) y d de los p dígitos están a la derecha del punto decimal. Por lo tanto, numeric(3, 1) permite almacenar 44.5 exactamente, pero ni 444.5 ni 0.32 pueden ser almacenados exactamente en un campo de este tipo.
real, double precision: números de punto flotante2 y punto flotante de doble precisión con precisión dependiente de la computadora.
float(n): número de punto flotante con precisión de al menos n dígitos.
Cada tipo puede incluir un valor especial llamado el valor null (nulo). Un valor nulo indica un valor ausente que puede existir pero ser desconocido o que puede no existir en absoluto. En ciertos casos, se podría querer prohibir que se ingresen valores nulos.
En esta sección se trabaja con las tablas de la base de datos university, como ejemplo. Se recomienda crear la base de datos en un SABD y reproducir los comandos.
CREATE TABLE#
En SQL, una tabla se define con la sentencia CREATE TABLE, en la que se especifican los nombres de las columnas juntos con sus tipos de datos. También pueden especificarse restricciones de llave primaria, llaves foráneas y prohibición de valores nulos, entre otras.
Sintaxis básica#
Se presentan dos variantes.
-- Creación de una tabla mediante la especificación de sus columnas,
-- tipos de datos y restricciones.
CREATE TABLE tabla (
columna1 tipo_datos,
columna2 tipo_datos NOT NULL,
columna3 tipo_datos,
....,
PRIMARY KEY(columna_llave_primaria),
FOREIGN KEY(columna_llave_foranea) REFERENCES tabla_referenciada,
....
);
-- Creación de una tabla a partir de la estructura de una tabla existente
CREATE TABLE tabla AS
SELECT columna1, columna2,...
FROM tabla_existente
WHERE ....;
Ejemplos#
El siguiente comando crea la tabla department:
-- Creación de la tabla department
CREATE TABLE department (
dept_name VARCHAR(20),
building VARCHAR(15),
budget NUMERIC(12,2),
PRIMARY KEY(dept_name)
);
La tabla que se crea a partir del comando anterior tiene tres columnas (dept_name, building, budget) y una de ellas (dept_name) es la llave primaria.
Los siguientes comandos crean las tablas instructor y student.
-- Creación de la tabla instructor
CREATE TABLE instructor (
ID VARCHAR(5),
name VARCHAR(20) NOT NULL,
dept_name VARCHAR(20),
salary NUMERIC(8,2),
PRIMARY KEY(ID),
FOREIGN KEY(dept_name) REFERENCES department
);
-- Creación de la tabla student
CREATE TABLE student (
ID VARCHAR(5),
name VARCHAR(20) NOT NULL,
dept_name VARCHAR(20),
tot_cred NUMERIC(3,0),
PRIMARY KEY(ID),
FOREIGN KEY(dept_name) REFERENCES department
);
Note las restricciones de atributos no nulos y de llaves foráneas.
Por último, los siguientes comandos crean las tablas course, section, teaches y takes.
-- Creación de la tabla course
CREATE TABLE course (
course_id VARCHAR(8),
title VARCHAR(50),
dept_name VARCHAR(20),
credits NUMERIC(2,0),
PRIMARY KEY(course_id),
FOREIGN KEY(dept_name) REFERENCES department
);
-- Creación de la tabla section
CREATE TABLE section (
course_id VARCHAR(8),
sec_id VARCHAR(8),
semester VARCHAR(6),
year NUMERIC(4,0),
building VARCHAR(15),
room_number VARCHAR(7),
time_slot_id VARCHAR(4),
PRIMARY KEY(course_id, sec_id, semester, year),
FOREIGN KEY(course_id) REFERENCES course
);
-- Creación de la relación teaches
CREATE TABLE teaches(
ID VARCHAR(5),
course_id VARCHAR(8),
sec_id VARCHAR(8),
semester VARCHAR(6),
year NUMERIC(4,0),
PRIMARY KEY(ID, course_id, sec_id, semester, year),
FOREIGN KEY(course_id, sec_id, semester, year) REFERENCES section,
FOREIGN KEY(ID) REFERENCES instructor
);
-- Creación de la tabla takes
CREATE TABLE takes (
ID VARCHAR(5),
course_id VARCHAR(8),
sec_id VARCHAR(8),
semester VARCHAR(6),
year NUMERIC(4,0),
grade NUMERIC(3,0),
PRIMARY KEY(ID, course_id, sec_id, semester, year) ,
FOREIGN KEY(ID) REFERENCES student,
FOREIGN KEY(course_id, sec_id, semester, year) REFERENCES section
);
El comando CREATE TABLE puede usarse en combinación con la cláusula AS y la sentencia SELECT para crear una tabla a partir de la estructura de una tabla existente, de la cual pueden seleccionarse todas o algunas columnas. Los datos de la tabla existente pueden cargarse en la nueva tabla.
-- Creación de una tabla que contiene los estudiantes aprobados
-- de la tabla takes y usa su misma estructura
CREATE TABLE takes_passed_students AS
SELECT *
FROM takes
WHERE grade >= 70;
La sentencia SELECT se explicará con mayor detalle en este capítulo.
ALTER TABLE#
La sentencia ALTER TABLE se utiliza para agregar, modificar o borrar columnas en una tabla. También puede agregar y borrar restricciones.
Con los siguientes comandos, se crea una tabla de ejemplo y luego se agrega, modifica y borra una columna, mediante ALTER TABLE. También se define la llave primaria de la tabla.
Sintaxis básica#
-- Adición de una columna
ALTER TABLE tabla
ADD columna tipo_datos;
-- Modificación del tipo de datos de una columna (sintaxis de PostgreSQL)
ALTER TABLE tabla
ALTER COLUMN columna TYPE tipo_datos;
-- Definición de llave primaria
ALTER TABLE tabla
ADD PRIMARY KEY(columna1, columna2, ...);
-- Borrado de una columna
ALTER TABLE tabla
DROP COLUMN columna;
Ejemplos#
-- Creación de una tabla de ejemplo
CREATE TABLE ejemplo (
col1 INTEGER
);
-- Adición de una columna
ALTER TABLE ejemplo
ADD col2 NUMERIC(3,0);
-- Modificación del tipo de datos de una columna (sintaxis de PostgreSQL)
ALTER TABLE ejemplo
ALTER COLUMN col2 TYPE INTEGER;
-- Definición de llave primaria
ALTER TABLE ejemplo
ADD PRIMARY KEY(col1, col2);
-- Borrado de una columna
ALTER TABLE ejemplo
DROP COLUMN col2;
TRUNCATE TABLE#
La sentencia TRUNCATE TABLE borra los datos de una tabla, pero no la tabla en sí misma.
Sintaxis básica#
TRUNCATE TABLE tabla;
Ejemplos#
-- Borrado de los datos de una tabla
TRUNCATE TABLE ejemplo;
DROP TABLE#
La sentencia DROP TABLE se utiliza para borrar una tabla.
Sintaxis básica#
DROP TABLE tabla;
Ejemplos#
-- Borrado de una tabla
DROP TABLE ejemplo;
SQL DML - Manipulación de datos#
Los comandos de SQL DML se utilizan para manipular los datos almacenados en una base de datos. Estos comandos incluyen INSERT, UPDATE y DELETE.
INSERT#
El comando INSERT inserta nuevos registros en una tabla.
Sintaxis básica#
Se presentan dos variantes.
-- Especificación de las columnas y sus respectivos valores
INSERT INTO tabla
(columna1, columna2, columna3, ...)
VALUES (valor1, valor2, valor3, ...);
-- Especificación de los valores únicamente.
-- Es útil si se usan todas las columnas.
-- Debe respetarse el orden en el que las columnas fueron definidas.
INSERT INTO tabla
VALUES (valor1, valor2, valor3, ...);
Ejemplos#
-- Inserción de un registro en la tabla department,
-- especificando las columnas y sus respectivos valores.
INSERT INTO department
(dept_name, building, budget)
VALUES ('Informática', 'Edificio A', 50000.00);
-- Inserción de un registro en la tabla department,
-- especificando solo los valores.
INSERT INTO department
VALUES ('Matemáticas', 'Edificio B', 45000.00);
Con el fin de proporcionar datos para los siguientes ejercicios, seguidamente se proporcionan comandos INSERT para las restantes tablas de la base de datos university.
Inserción de registros en la tabla instructor
-- Inserción de registros en la tabla instructor
INSERT INTO instructor
(ID, name, dept_name, salary)
VALUES ('I001', 'Juan Pérez', 'Informática', 35000.00);
INSERT INTO instructor
(ID, name, dept_name, salary)
VALUES ('I002', 'María García', 'Informática', 36000.00);
INSERT INTO instructor
(ID, name, dept_name, salary)
VALUES ('I003', 'Carlos Rodríguez', 'Matemáticas', 34000.00);
INSERT INTO instructor
(ID, name, dept_name, salary)
VALUES ('I004', 'Ana Torres', 'Matemáticas', 33000.00);
INSERT INTO instructor
(ID, name, dept_name, salary)
VALUES ('I005', 'Luisa Fernández', 'Informática', 35500.00);
Inserción de registros en la tabla student
-- Inserción de registros en la tabla student
INSERT INTO student VALUES ('S001', 'Alejandro Ruiz', 'Informática', 50);
INSERT INTO student VALUES ('S002', 'Beatriz Morales', 'Informática', 52);
INSERT INTO student VALUES ('S003', 'Carlos Vargas', 'Informática', 48);
INSERT INTO student VALUES ('S004', 'Daniela Ortega', 'Informática', 55);
INSERT INTO student VALUES ('S005', 'Eduardo Paredes', 'Informática', 51);
INSERT INTO student VALUES ('S006', 'Fernanda Castillo', 'Informática', 53);
INSERT INTO student VALUES ('S007', 'Gabriel Mendoza', 'Informática', 49);
INSERT INTO student VALUES ('S008', 'Hilda Navarro', 'Informática', 54);
INSERT INTO student VALUES ('S009', 'Iván Duarte', 'Informática', 50);
INSERT INTO student VALUES ('S010', 'Jessica Alvarado', 'Informática', 52);
INSERT INTO student VALUES ('S011', 'Kevin Romero', 'Informática', 48);
INSERT INTO student VALUES ('S012', 'Liliana Pérez', 'Informática', 55);
INSERT INTO student VALUES ('S013', 'Miguel Ángel Soto', 'Informática', 51);
INSERT INTO student VALUES ('S014', 'Natalia Gómez', 'Informática', 53);
INSERT INTO student VALUES ('S015', 'Oscar Hernández', 'Informática', 49);
INSERT INTO student VALUES ('S016', 'Patricia Lugo', 'Informática', 54);
INSERT INTO student VALUES ('S017', 'Raúl Torres', 'Informática', 50);
INSERT INTO student VALUES ('S018', 'Sofía Méndez', 'Informática', 52);
INSERT INTO student VALUES ('S019', 'Tomás Cervantes', 'Informática', 48);
INSERT INTO student VALUES ('S020', 'Ursula Vázquez', 'Informática', 55);
INSERT INTO student VALUES ('S021', 'Víctor Delgado', 'Matemáticas', 50);
INSERT INTO student VALUES ('S022', 'Wendy Olvera', 'Matemáticas', 52);
INSERT INTO student VALUES ('S023', 'Ximena Ponce', 'Matemáticas', 48);
INSERT INTO student VALUES ('S024', 'Yahir Ríos', 'Matemáticas', 55);
INSERT INTO student VALUES ('S025', 'Zoe Salinas', 'Matemáticas', 51);
INSERT INTO student VALUES ('S026', 'Andrés Mora', 'Matemáticas', 53);
INSERT INTO student VALUES ('S027', 'Blanca Estela', 'Matemáticas', 49);
INSERT INTO student VALUES ('S028', 'Cecilia Rojas', 'Matemáticas', 54);
INSERT INTO student VALUES ('S029', 'Diego Lira', 'Matemáticas', 50);
INSERT INTO student VALUES ('S030', 'Elena Barrios', 'Matemáticas', 52);
INSERT INTO student VALUES ('S031', 'Roberto Silva', 'Informática', 53);
INSERT INTO student VALUES ('S032', 'Isabel Marín', 'Informática', 50);
INSERT INTO student VALUES ('S033', 'Felipe Guzmán', 'Informática', 52);
INSERT INTO student VALUES ('S034', 'Lorena Ríos', 'Informática', 55);
INSERT INTO student VALUES ('S035', 'Guillermo Paredes', 'Informática', 49);
INSERT INTO student VALUES ('S036', 'Rosa Mendoza', 'Informática', 51);
INSERT INTO student VALUES ('S037', 'Javier Castillo', 'Informática', 53);
INSERT INTO student VALUES ('S038', 'Carmen Lugo', 'Informática', 50);
INSERT INTO student VALUES ('S039', 'Luis Méndez', 'Informática', 52);
INSERT INTO student VALUES ('S040', 'Diana Herrera', 'Informática', 55);
INSERT INTO student VALUES ('S041', 'Ricardo Gómez', 'Informática', 49);
INSERT INTO student VALUES ('S042', 'Mónica Soto', 'Informática', 51);
INSERT INTO student VALUES ('S043', 'Ernesto Vázquez', 'Informática', 53);
INSERT INTO student VALUES ('S044', 'Sandra Ponce', 'Informática', 50);
INSERT INTO student VALUES ('S045', 'Alberto Cervantes', 'Informática', 52);
INSERT INTO student VALUES ('S046', 'Patricia Delgado', 'Informática', 55);
INSERT INTO student VALUES ('S047', 'Francisco Navarro', 'Informática', 49);
INSERT INTO student VALUES ('S048', 'Martha Ortega', 'Informática', 51);
INSERT INTO student VALUES ('S049', 'Gabriela Torres', 'Informática', 53);
INSERT INTO student VALUES ('S050', 'Jorge Alvarado', 'Informática', 50);
INSERT INTO student VALUES ('S051', 'Laura Romero', 'Matemáticas', 52);
INSERT INTO student VALUES ('S052', 'Ramón Duarte', 'Matemáticas', 55);
INSERT INTO student VALUES ('S053', 'Susana Olvera', 'Matemáticas', 49);
INSERT INTO student VALUES ('S054', 'Mario Paredes', 'Matemáticas', 51);
INSERT INTO student VALUES ('S055', 'Teresa Vargas', 'Matemáticas', 53);
INSERT INTO student VALUES ('S056', 'José Luis Morales', 'Matemáticas', 50);
INSERT INTO student VALUES ('S057', 'Adriana Ruiz', 'Matemáticas', 52);
INSERT INTO student VALUES ('S058', 'Pedro García', 'Matemáticas', 55);
INSERT INTO student VALUES ('S059', 'Verónica Castillo', 'Matemáticas', 49);
INSERT INTO student VALUES ('S060', 'Manuel Navarro', 'Matemáticas', 51);
Inserción de registros en la tabla course
-- Inserción de registros en la tabla course
INSERT INTO course VALUES ('C001', 'Programación Básica', 'Informática', 4);
INSERT INTO course VALUES ('C002', 'Redes y Comunicaciones', 'Informática', 3);
INSERT INTO course VALUES ('C003', 'Bases de Datos', 'Informática', 4);
INSERT INTO course VALUES ('C004', 'Álgebra Lineal', 'Matemáticas', 4);
INSERT INTO course VALUES ('C005', 'Cálculo Diferencial', 'Matemáticas', 4);
INSERT INTO course VALUES ('C006', 'Estadística y Probabilidad', 'Matemáticas', 3);
Inserción de registros en la tabla section
-- Inserción de registros en la tabla section
INSERT INTO section VALUES ('C001', 'SEC01', 'S2', 2022, 'Edificio A', '101', 'TS01');
INSERT INTO section VALUES ('C002', 'SEC01', 'S1', 2023, 'Edificio A', '201', 'TS01');
INSERT INTO section VALUES ('C002', 'SEC02', 'S1', 2023, 'Edificio A', '202', 'TS04');
INSERT INTO section VALUES ('C003', 'SEC01', 'S1', 2022, 'Edificio C', '301', 'TS05');
INSERT INTO section VALUES ('C003', 'SEC02', 'S1', 2022, 'Edificio C', '302', 'TS06');
INSERT INTO section VALUES ('C004', 'SEC01', 'S2', 2023, 'Edificio B', '101', 'TS02');
INSERT INTO section VALUES ('C004', 'SEC02', 'S2', 2023, 'Edificio B', '102', 'TS02');
INSERT INTO section VALUES ('C005', 'SEC01', 'S1', 2022, 'Edificio B', '501', 'TS01');
INSERT INTO section VALUES ('C006', 'SEC01', 'S1', 2023, 'Edificio B', '601', 'TS07');
INSERT INTO section VALUES ('C006', 'SEC02', 'S1', 2023, 'Edificio B', '602', 'TS07');
Inserción de registros en la tabla teaches
-- Inserción de registros en la tabla teaches
INSERT INTO teaches VALUES ('I001', 'C001', 'SEC01', 'S2', 2022);
INSERT INTO teaches VALUES ('I002', 'C002', 'SEC01', 'S1', 2023);
INSERT INTO teaches VALUES ('I002', 'C002', 'SEC02', 'S1', 2023);
INSERT INTO teaches VALUES ('I003', 'C003', 'SEC01', 'S1', 2022);
INSERT INTO teaches VALUES ('I003', 'C003', 'SEC02', 'S1', 2022);
INSERT INTO teaches VALUES ('I004', 'C004', 'SEC01', 'S2', 2023);
INSERT INTO teaches VALUES ('I004', 'C004', 'SEC02', 'S2', 2023);
INSERT INTO teaches VALUES ('I005', 'C005', 'SEC01', 'S1', 2022);
INSERT INTO teaches VALUES ('I001', 'C006', 'SEC01', 'S1', 2023);
INSERT INTO teaches VALUES ('I002', 'C006', 'SEC02', 'S1', 2023);
Inserción de registros en la tabla takes
-- Inserción de registros en la tabla takes
-- Estudiantes para C001 SEC01 S2 2022
INSERT INTO takes VALUES ('S001', 'C001', 'SEC01', 'S2', 2022, 85);
INSERT INTO takes VALUES ('S002', 'C001', 'SEC01', 'S2', 2022, 78);
INSERT INTO takes VALUES ('S003', 'C001', 'SEC01', 'S2', 2022, 90);
INSERT INTO takes VALUES ('S004', 'C001', 'SEC01', 'S2', 2022, 65);
INSERT INTO takes VALUES ('S005', 'C001', 'SEC01', 'S2', 2022, 72);
-- Estudiantes para C002 SEC01 S1 2023
INSERT INTO takes VALUES ('S006', 'C002', 'SEC01', 'S1', 2023, 88);
INSERT INTO takes VALUES ('S007', 'C002', 'SEC01', 'S1', 2023, 69);
INSERT INTO takes VALUES ('S008', 'C002', 'SEC01', 'S1', 2023, 74);
INSERT INTO takes VALUES ('S001', 'C002', 'SEC01', 'S1', 2023, 82);
INSERT INTO takes VALUES ('S002', 'C002', 'SEC01', 'S1', 2023, 76);
-- Estudiantes para C002 SEC02 S1 2023
INSERT INTO takes VALUES ('S009', 'C002', 'SEC02', 'S1', 2023, 91);
INSERT INTO takes VALUES ('S010', 'C002', 'SEC02', 'S1', 2023, 67);
INSERT INTO takes VALUES ('S011', 'C002', 'SEC02', 'S1', 2023, 95);
INSERT INTO takes VALUES ('S012', 'C002', 'SEC02', 'S1', 2023, 60);
INSERT INTO takes VALUES ('S013', 'C002', 'SEC02', 'S1', 2023, 73);
-- Estudiantes para C003 SEC01 S1 2022
INSERT INTO takes VALUES ('S014', 'C003', 'SEC01', 'S1', 2022, 89);
INSERT INTO takes VALUES ('S015', 'C003', 'SEC01', 'S1', 2022, 70);
INSERT INTO takes VALUES ('S016', 'C003', 'SEC01', 'S1', 2022, 92);
INSERT INTO takes VALUES ('S003', 'C003', 'SEC01', 'S1', 2022, 64);
INSERT INTO takes VALUES ('S004', 'C003', 'SEC01', 'S1', 2022, 79);
-- Estudiantes para C003 SEC02 S1 2022
INSERT INTO takes VALUES ('S017', 'C003', 'SEC02', 'S1', 2022, 87);
INSERT INTO takes VALUES ('S018', 'C003', 'SEC02', 'S1', 2022, 68);
INSERT INTO takes VALUES ('S019', 'C003', 'SEC02', 'S1', 2022, 93);
INSERT INTO takes VALUES ('S020', 'C003', 'SEC02', 'S1', 2022, 62);
INSERT INTO takes VALUES ('S021', 'C003', 'SEC02', 'S1', 2022, 75);
-- Estudiantes para C004 SEC01 S2 2023
INSERT INTO takes VALUES ('S022', 'C004', 'SEC01', 'S2', 2023, 86);
INSERT INTO takes VALUES ('S023', 'C004', 'SEC01', 'S2', 2023, 71);
INSERT INTO takes VALUES ('S024', 'C004', 'SEC01', 'S2', 2023, 94);
INSERT INTO takes VALUES ('S005', 'C004', 'SEC01', 'S2', 2023, 63);
INSERT INTO takes VALUES ('S006', 'C004', 'SEC01', 'S2', 2023, 80);
-- Estudiantes para C004 SEC02 S2 2023
INSERT INTO takes VALUES ('S025', 'C004', 'SEC02', 'S2', 2023, 84);
INSERT INTO takes VALUES ('S026', 'C004', 'SEC02', 'S2', 2023, 66);
INSERT INTO takes VALUES ('S027', 'C004', 'SEC02', 'S2', 2023, 96);
INSERT INTO takes VALUES ('S028', 'C004', 'SEC02', 'S2', 2023, 61);
INSERT INTO takes VALUES ('S029', 'C004', 'SEC02', 'S2', 2023, 77);
-- Estudiantes para C005 SEC01 S1 2022
INSERT INTO takes VALUES ('S030', 'C005', 'SEC01', 'S1', 2022, 83);
INSERT INTO takes VALUES ('S031', 'C005', 'SEC01', 'S1', 2022, 72);
INSERT INTO takes VALUES ('S032', 'C005', 'SEC01', 'S1', 2022, 97);
INSERT INTO takes VALUES ('S007', 'C005', 'SEC01', 'S1', 2022, 59);
INSERT INTO takes VALUES ('S008', 'C005', 'SEC01', 'S1', 2022, 81);
-- Estudiantes para C006 SEC01 S1 2023
INSERT INTO takes VALUES ('S033', 'C006', 'SEC01', 'S1', 2023, 85);
INSERT INTO takes VALUES ('S034', 'C006', 'SEC01', 'S1', 2023, 73);
INSERT INTO takes VALUES ('S035', 'C006', 'SEC01', 'S1', 2023, 98);
INSERT INTO takes VALUES ('S009', 'C006', 'SEC01', 'S1', 2023, 58);
INSERT INTO takes VALUES ('S010', 'C006', 'SEC01', 'S1', 2023, 82);
-- Estudiantes para C006 SEC02 S1 2023
INSERT INTO takes VALUES ('S036', 'C006', 'SEC02', 'S1', 2023, 82);
INSERT INTO takes VALUES ('S037', 'C006', 'SEC02', 'S1', 2023, 74);
INSERT INTO takes VALUES ('S038', 'C006', 'SEC02', 'S1', 2023, 99);
INSERT INTO takes VALUES ('S039', 'C006', 'SEC02', 'S1', 2023, 57);
INSERT INTO takes VALUES ('S040', 'C006', 'SEC02', 'S1', 2023, 76);
UPDATE#
El comando UPDATE modifica registros de una tabla.
Sintaxis básica#
UPDATE tabla
SET columna1 = valor1, columna2 = valor2, ...
WHERE condición;
Ejemplos#
-- Aumento de un 5% a los salarios de todos los profesores
UPDATE instructor
SET salary = salary * 1.05;
-- Aumento de un 5% de los salarios de los profesores
-- con salarios menores a 35000
UPDATE instructor
SET salary = salary * 1.05
WHERE salary < 35000;
-- Aumento de un 5% de los salarios de los profesores
-- con salarios menores al promedio de todos los salarios.
-- Se utiliza una subconsulta.
UPDATE instructor
SET salary = salary * 1.05
WHERE salary < (SELECT AVG(salary) FROM instructor);
DELETE#
El comando DELETE borra registros de una tabla.
Sintaxis básica#
DELETE FROM tabla WHERE condición;
Ejemplos#
-- Borrado de un estudiante por ID
DELETE FROM student WHERE ID = 'S060';
Ejercicios#
Agregue registros de prueba en las tablas de la base de datos
universityde acuerdo con los siguientes pasos:Agregue el departamento ‘Geografía’ en la tabla
department.Agregue el estudiante ‘Alexander von Humboldt’ en la tabla
student. Asígnelo al departamento de Geografía.Agregue el profesor ‘Eratóstenes’ en la tabla
instructor. Asígnelo al departamento de Geografía.Agregue el curso ‘Fundamentos de la Geodesia’ en la tabla
course. Asígnelo al departamento de Geografía.Agregue el grupo ‘G001’ del curso ‘Fundamentos de la Geodesia’, que se imparte en el segundo semestre de 2023, en la tabla
section.En la tabla
teaches, asigne el grupo ‘G001’ de ‘Fundamentos de la Geodesia’, segundo semestre 2023, al profesor Eratóstenes.En la tabla
takes, matricule al estudiante Alexander von Humboldt en el grupo ‘G001’ de ‘Fundamentos de la Geodesia’, segundo semestre 2023.
Agregue más registros de departamentos, estudiantes, profesores, cursos, grupos y demás. Intente cambiar el orden de las inserciones y observe los resultados.
DQL - Consulta de datos#
En esta sección, se estudia la sentencia SELECT y sus diferentes cláusulas para consulta de datos.
La sentencia SELECT y las cláusulas FROM y WHERE#
Las consultas de datos en SQL se realizan a través de la sentencia SELECT y su clásula FROM. Es muy frecuente usar también la cláusula WHERE, pero no es obligatoria. Con SELECT se especifican las columnas que retorna la consulta, las cuales provienen de las tablas listadas en FROM. WHERE contiene una expresión lógica que deben satisfacer los registros y que puede contener operadores lógicos como AND, OR y NOT.
Sintaxis básica#
SELECT columna1, columna2, ...
FROM tabla
WHERE condición
Ejemplos#
-- Consulta de todos los registros y todas las columnas de la tabla student.
-- El asterisco ("estrella") indica que deben retornarse todas las columnas.
SELECT *
FROM student;
-- Consulta de todos los registros y las columnas ID, name y dept_name de la tabla student
SELECT ID, name, dept_name
FROM student;
-- Valores distintos de la columna dept_name en la tabla student
SELECT DISTINCT dept_name
FROM student;
-- Cláusula WHERE con una expresión lógica
SELECT *
FROM student
WHERE dept_name = 'Informática' AND tot_cred >= 55;
Algunas operaciones básicas#
En esta sección, se introducen varias operaciones que se utilizan comúnmente en consultas SQL.
La palabra clave AS#
La palabra clave AS se utiliza para asignar un alias temporal a una columna o tabla. Este alias solamente existe durante la duración de la consulta.
Por ejemplo, considere la siguiente consulta con una columna que se calcula a partir de otra columna.
-- Consulta con columna calculada
SELECT
name,
salary,
salary * 1.05
FROM instructor;
La columna que se calcula a partir de otra (salary * 1.05) tendrá un nombre poco significativo en el despliegue de los resultados (ej. ?column?). Para darle un nombre más representativo, se le puede asignar un alias con AS.
-- Alias temporal asignado con la cláusula AS
SELECT
name,
salary,
salary * 1.05 AS projected_salary
FROM instructor;
-- Varios alias temporales asignados con la cláusula AS.
-- En el último se usan comillas dobles, debido los espacios.
SELECT
name AS nombre,
salary AS salario,
salary * 1.05 AS "salario proyectado"
FROM instructor;
AS también puede utilizarse para asignarle alias a tablas. Por ejemplo, la consulta:
-- Consulta con nombres completos de tablas
SELECT name AS instructor_name, course_id
FROM instructor, teaches
WHERE instructor.ID = teaches.ID;
puede reescribirse, mediante alias, como:
-- Consulta con alias para las tablas
SELECT name AS instructor_name, course_id
FROM instructor AS i, teaches AS t
WHERE i.ID = t.ID;
En este último caso, AS se utiliza para acortar los nombres de las tablas mediante alias y así referenciarlas más fácilmente en la cláusula WHERE. Esto es particularmente útil cuando los nombres de las tablas son muy largos y deben usarse muchas veces en la consulta.
Operaciones con hileras de caracteres#
En SQL, las hileras de caracteres (textos), se especifican colocándolos entre comillas simples, por ejemplo: ‘universidad’. Una comilla simple que forma parte de una hilera se puede especificar usando dos caracteres de comillas simples; por ejemplo, la cadena “It’s right” se puede especificar en SQL como ‘It’’s right’ [SKS19].
El estándar SQL establece que la operación de igualdad en hileras es sensible a mayúsculas y minúsculas. Así, la expresión 'Universidad' = 'universidad' se evalúa como falsa. Sin embargo, algunos SABD, como MySQL y SQL Server, no distinguen entre mayúsculas y minúsculas al comparar hileras. Este funcionamiento predeterminado puede modificarse [SKS19].
-- La siguiente consulta a la BD university retorna un registro (en PostgreSQL)
SELECT *
FROM instructor
WHERE name = 'María García';
-- La siguiente consulta a la BD university no retorna ningún registro (en PostgreSQL)
SELECT *
FROM instructor
WHERE name = 'MARÍA GARCÍA';
SQL permite una variedad de funciones en hileras de caracteres, como concatenar (mediante el operador ||), extraer subhileras, encontrar la longitud de las hileras, convertir hileras a mayúsculas (mediante la función UPPER(s) donde s es una hilera) y a minúsculas (mediante la función LOWER(s)), eliminar espacios al final de la cadena (mediante TRIM(s)) y otras. Hay variaciones en el conjunto exacto de funciones de hileras de caracteres que son soportadas por diferentes SABD [SKS19].
-- Concatenación de hileras
SELECT 'Identificación: ' || ID || ', Nombre: ' || name
FROM instructor;
-- Conversión a mayúsculas y minúsculas
SELECT UPPER(name), LOWER(dept_name)
FROM instructor;
La coincidencia de patrones (pattern matching) se realiza en SQL mediante el operador LIKE. Los patrones se describen con dos caracteres especiales:
Porcentaje (
%): coincide con cualquier subcadena.Guion bajo (
_): coincide con cualquier carácter.
-- Estudiantes con nombres que empiezan con 'A'
SELECT *
FROM student
WHERE name LIKE 'A%';
-- Estudiantes con nombres que empiezan con 'Gab'
SELECT *
FROM student
WHERE name LIKE 'Gab%';
-- Estudiantes con nombres con 'w' en cualquier parte
SELECT *
FROM student
WHERE name LIKE '%w%';
-- Estudiantes con nombres con la letra 'H' o 'h' en cualquier parte
SELECT *
FROM student
WHERE name LIKE '%H%' OR name LIKE '%h%';
-- Estudiantes con nombres en los que la primera letra es 'D' y la tercera letra es 'n'
SELECT *
FROM student
WHERE name LIKE 'D_n%';
Predicados en la cláusula WHERE#
Como se explicó en un sección previa, la cláusula WHERE contiene predicados (i.e. expresiones lógicas que pueden ser verdaderas, falsas o desconocidas) que deben satisfacer los registros que retorne la consulta.
El operador BETWEEN#
El operador BETWEEN selecciona valores en un rango. Estos valores pueden ser números, caracteres o fechas.
Por ejemplo, la consulta:
-- Consulta de rango de números entre 80 y 90 (inclusive)
-- mediante los operadores >= y <=
SELECT ID, grade
FROM takes
WHERE grade >= 80 AND grade <= 90;
puede reescribirse como:
-- Consulta de rango de números entre 80 y 90 (inclusive)
-- mediante el operador BETWEEN
SELECT ID, grade
FROM takes
WHERE grade BETWEEN 80 AND 90;
BETWEEN también puede emplearse para consultar rangos de hileras de caracteres.
-- Consulta de hileras entre 'Alejandro Ruiz' y 'Daniela Ortega'
SELECT name
FROM student
WHERE name BETWEEN 'Alejandro Ruiz' AND 'Daniela Ortega';
El operador IN#
El operador IN permite especificar múltiples valores en una cláusula WHERE. Puede utilizarse para abreviar un predicado con múltiples OR.
Considere la siguiente consulta de múltiples valores, mediante varios OR:
-- Consulta de estudiantes con ID específicos
-- mediante múltiples OR
SELECT ID, name
FROM student
WHERE ID = 'S001' OR ID = 'S002' OR ID = 'S003';
Mediante IN, puede reescribirse como:
-- Consulta de estudiantes con ID específicos
-- mediante el operador IN
SELECT ID, name
FROM student
WHERE ID IN ('S001', 'S002', 'S003');
La cláusula ORDER BY#
ORDER BY se utiliza para ordenar los resultados de una consulta en orden ascendente o descendente. El orden ascendente es el que se usa por defecto. Si se requiere de un orden descendente, debe usarse la palabra reservada DESC.
Sintaxis básica#
SELECT columna1, columna2, ...
FROM tabla
ORDER BY columna1, columna2, ... ASC|DESC;
Ejemplos#
-- Grupos de cursos ordenados por año y semestre
SELECT course_id, year, semester
FROM section
ORDER BY year, semester;
-- Profesores ordenados por salario en orden descendente
SELECT salary, name
FROM instructor
ORDER BY salary DESC;
Funciones de agregación#
Las funciones de agregación reciben como entrada un conjunto de valores y retornan un solo valor. El estándar de SQL incluye cinco funciones, pero los SABD acostumbran añadir otras [SKS19].
La entrada de AVG() y SUM() debe ser un conjunto de números, pero el resto de las funciones acepta también otros tipos de datos, como hileras de caracteres.
Agregación sin agrupación#
El resultado de este tipo de consultas es una relación con un único atributo que contiene una única tupla con un valor numérico correspondiente al resultado de la función de agregación. El SABD puede asignar un nombre poco significativo al atributo de la relación resultante, consistente en el texto de la expresión; sin embargo, podemos darle un nombre significativo al atributo utilizando la cláusula AS [SKS19].
-- Salario promedio de todos los profesores
SELECT AVG(salary)
FROM instructor;
-- Salario promedio de los profesores del departamento de matemáticas.
-- Se usa la cláusula AS para renombrar la columna resultante del cálculo
SELECT AVG(salary) AS salario_promedio
FROM instructor
WHERE dept_name = 'Matemáticas';
-- Salario promedio de los profesores del departamento de informática
SELECT AVG(salary) AS salario_promedio
FROM instructor
WHERE dept_name = 'Informática';
En algunos casos, es necesario eliminar valores duplicados antes de ejecutar la función de agregación. Para eso, puede utilizarse la palabra reservada DISTINCT.
-- Cantidad de cursos (diferentes) que se impartieron en el año 2022
SELECT COUNT(DISTINCT course_id)
FROM section
WHERE year = 2022;
-- Lista de cursos (diferentes) que se impartieron en el año 2022
SELECT DISTINCT course_id
FROM section
WHERE year = 2022;
Para apreciar las diferencias, ejecute los ejemplos anteriores sin usar DISTINCT.
Agregación con agrupación#
La cláusula GROUP BY permite aplicar la función de agregación no solo a un conjunto único de tuplas, sino también a un grupo de conjuntos de tuplas. El atributo o atributos proporcionados en la cláusula GROUP BY se utilizan para formar grupos. Las tuplas con el mismo valor en todos los atributos en la cláusula GROUP BY se colocan en un grupo.
-- Salario promedio de los profesores, agrupados por departamento
SELECT dept_name, AVG(salary) AS salario_promedio
FROM instructor
GROUP BY dept_name;
-- Cantidad de estudiantes matriculados en cada año y semestre
SELECT year, semester, COUNT(*) AS estudiantes_matriculados
FROM section
GROUP BY year, semester
ORDER BY year, semester;
En el ejemplo anterior, note que las columnas listadas en la cláusula GROUP BY también están presentes en la cláusula SELECT.
La cláusula HAVING#
La cláusula HAVING especifica una condición que se aplica a los grupos formados por GROUP BY y no a los registros.
-- Cantidad de estudiantes matriculados en cada año y semestre
-- con cantidades mayores o iguales a cuatro
SELECT year, semester, COUNT(*) AS estudiantes_matriculados
FROM section
GROUP BY year, semester
HAVING COUNT(*) >= 4
ORDER BY year, semester;
La cláusula CASE#
La cláusula CASE permite implementar lógica condicional en una consulta. CASE recorre una secuencia de condiciones, retorna un valor al encontrar la primera condición verdadera y no evalúa las condiciones restantes. Si ninguna condición es verdadera, devuelve el valor en la cláusula ELSE. Si no hay una cláusula ELSE y ninguna condición es verdadera, devuelve NULL.
Sintaxis básica#
-- Sintaxis básica de CASE
CASE
WHEN condición1 THEN valor_retorno_1
WHEN condición2 THEN valor_retorno_2
...
WHEN condiciónN THEN valor_retorno_n
ELSE valor_retorno_else
END;
Ejemplos#
-- Creación de un campo en la tabla takes con el resultado del curso:
-- Reprobado, Ampliación o Aprobado
SELECT ID, course_id, sec_id, semester, year, grade,
CASE
WHEN grade < 57.5 THEN 'Reprobado'
WHEN grade >= 57.5 AND grade < 70 THEN 'Ampliación'
ELSE 'Aprobado'
END AS Resultado
FROM takes;
Manejo de valores nulos#
Los valores nulos presentan problemas especiales en bases de datos relacionales, incluyendo operaciones aritméticas, operaciones de comparación y operaciones de conjuntos [SKS19].
El resultado de una expresión aritmética (que involucra, por ejemplo, +, -, * o /) es nulo si cualquiera de los valores de entrada es nulo.
Las comparaciones que involucran valores nulos son más problemáticas. Por ejemplo, considere la expresión 1 < NULL. Sería incorrecto decir que es verdadera o que es falsa, ya que no sabemos lo que el valor nulo representa. Por lo tanto, SQL trata como UNKNOWN (desconocido) el resultado de cualquier comparación que involucre un valor nulo (a excepción de los predicados IS NULL e IS NOT NULL, que se describen más adelante en esta sección). Esto crea un tercer valor lógico además de TRUE (verdadero) y FALSE (falso).
Ya que el predicado en una cláusula WHERE puede involucrar operadores lógicos como ABD, OR y NOT en los resultados de las comparaciones, las definiciones de estas operaciones se amplían para tratar con el valor UNKNOWN.
AND
TRUE AND UNKNOWNesUNKNOWNFALSE AND UNKNOWNesFALSEUNKNOWN AND UNKNOWNesUNKNOWN
OR
TRUE OR UNKNOWNesTRUEFALSE OR UNKNOWNesUNKNOWNUNKNOWN OR UNKNOWNesUNKNOWN
NOT
NOT UNKNOWNesUNKNOWN
Si el predicado de una cláusula WHERE se evalúa como FALSE o UNKNOWN para una tupla, es tupla no se añade al resultado [SKS19].
El predicado IS NULL#
SQL utiliza la palabra reservada NULL en un predicado para comprobar si un valor es nulo. Por ejemplo:
-- Nombres de profesores con salario nulo
SELECT name
FROM instructor
WHERE salary IS NULL;
-- Nombres de profesores con salario no nulo
SELECT name
FROM instructor
WHERE salary IS NOT NULL;
El predicado IS NULL puede usarse para contar la cantidad de valores nulos en una columna, en combinación con la expresión condicional CASE. Por ejemplo:
-- Conteo total de empleados, empleados con salario y empleados sin salario
SELECT
departamento,
COUNT(*) AS conteo_total_empleados,
SUM(CASE WHEN salario IS NOT NULL THEN 1 ELSE 0 END) AS conteo_empleados_con_salario,
SUM(CASE WHEN salario IS NULL THEN 1 ELSE 0 END) AS conteo_empleados_sin_salario
FROM empleados
GROUP BY departamento;
Funciones para comprobar valores nulos#
Los SABD incluyen diferentes funciones para verificar si un valor es nulo.
Por ejemplo, la función COALESCE() retorna el primer valor no nulo en una lista de expresiones. Es especialmente útil cuando se quiere proporcionar un valor por defecto en lugar de un valor nulo.
La sintaxis básica es la siguiente:
COALESCE(expresion1, expresion2, ..., expresionN)
Si expresion1 es nula, se verifica expresion2, y así sucesivamente, hasta encontrar un valor no nulo o llegar al final de la lista. Si todos los valores son nulos, COALESCE() retorna NULL.
Por ejemplo, suponga que se tiene una tabla llamada empleados con una columna salario y se desea seleccionar el salario de un empleado, pero si el salario es nulo, se desea que se retorne 0 en lugar de NULL.
SELECT COALESCE(salario, 0) FROM empleados;
Ejercicios#
Con consultas SQL en la base de datos
university, obtenga:Lista de estudiantes del departamento de matemáticas.
Cantidad de estudiantes del departamento de informática.
Año, grupo, curso y semestre con mayor cantidad de estudiantes matriculados.
Profesor que imparte la mayor cantidad de cursos.
Promedio de notas por curso (para todos los grupos, semestres y años).
Lista de ID de estudiantes con sus respectivos promedios de notas, para todos los años, semestres, grupos y cursos.
Promedio de estudiantes (para todos los años, semestres, grupos y cursos) cuyo nombre empieza con una vocal.
Con los datos de StatsBomb del partido final de la Copa Mundial de la FIFA Catar 2022 entre Argentina y Francia en formato CSV, obtenga:
Cantidad total de pases por equipo. Muestre el resultado en un gráfico de pastel.
Cantidad total de pases por jugador:
De Argentina. Muestre el resultado en un gráfico de barras.
De Francia. Muestre el resultado en un gráfico de barras.
Cantidad de pases completos (columna
pass_outcomecon valor nulo) por jugador:De Argentina. Muestre el resultado en un gráfico de barras.
De Francia. Muestre el resultado en un gráfico de barras.
Cantidad de pases incompletos (todos los que no son completos) por jugador:
De Argentina. Muestre el resultado en un gráfico de barras.
De Francia. Muestre el resultado en un gráfico de barras.
Porcentaje de pases completos, con respecto al total de pases, por jugador:
De Argentina. Muestre el resultado en un gráfico de barras.
De Francia. Muestre el resultado en un gráfico de barras.
Reúna, en una única tabla, la cantidad total de pases, la cantidad de pases completos y la cantidad de pases incompletos por jugador.
De Argentina.
De Francia.
Con los datos de StatsBomb de la fase de grupos de la Copa Mundial de la FIFA Catar 2022 en formato CSV, escriba una consulta para obtener:
Cantidad total de pases por equipo.
Cantidad de pases completos (columna
pass_outcomecon valor nulo) por equipo.Cantidad de pases incompletos (todos los que no son completos) por equipo.
Porcentaje de pases completos, con respecto al total de pases, por equipo.
Grafique los resultados.
Con los datos de StatsBomb, de la fase de grupos de la Copa Mundial de la FIFA Catar 2022 en formato CSV, escriba una consulta para obtener:
Cantidad total de tiros a marco por equipo.
Cantidad de tiros directos (columna
shot_outcomecon valores ‘Saved’, ‘Post’ o ‘Goal’) por equipo.Cantidad de tiros indirectos (todos los que no son directos) por equipo.
Porcentaje de tiros directos, con respecto al total de tiros a marco, por equipo.
Grafique los resultados.
Con los datos de StatsBomb, de la fase de grupos de la Copa Mundial de la FIFA Catar 2022 en formato CSV, escriba una consulta para obtener:
Suma de la longitud de los pases completos, por equipo.
Grafique los resultados.
Para verificar los resultados de los ejercicios sobre el Mundial Catar 2022, puede consultar los siguientes cuadernos de notas de Python:
Consultas en múltiples tablas#
En esta sección, se estudia como escribir consultas de datos que están distribuidos en varias tablas.
Por ejemplo, considere la consulta: obtener los nombres de todos los profesores, junto con los nombres de sus respectivos departamentos y los nombres de los edificios de los departamentos. Los nombres de los profesores y de sus departamentos están en la tabla instructor, pero los nombres de los edificios están en la tabla deparment. Para responder a la consulta, cada registro en instructor debe coincidir con el registro en departament cuyo valor de dept_name coincida con el valor de dept_name en instructor.
En SQL, una forma de responder a consultas como la anterior, consiste en listar todas las tablas que van a consultarse en la cláusula FROM y especificar la condición de coincidencia en la cláusula WHERE.
-- Nombres de profesores, departamentos y edificios
SELECT name, instructor.dept_name, building
FROM instructor, department
WHERE instructor.dept_name = department.dept_name;
Debido a que la columna dept_name está presente en ambas tablas, el nombre de la tabla se utiliza como prefijo (en instructor.dept_name y department.dept_name) para especificar a cual columna se está haciendo referencia en cada caso.
La siguiente consulta retorna los cursos impartidos por cada profesor, junto con la sección, año y semestre correspondientes.
-- course_id de cursos impartidos por cada profesor, junto con la sección, semestre y año
SELECT name, course_id, sec_id, year, semester
FROM instructor, teaches
WHERE instructor.ID = teaches.ID
ORDER BY name, course_id, sec_id, year, semester;
Nótese que la consulta anterior retorna solamente los nombres de profesores que han impartido al menos un curso. Si un profesor está presente en la tabla ìnstructor, pero no tiene ningún curso asignado en la tabla teaches, su nombre no se mostrará en el resultado.
Si se requiere incluir el nombre del curso en el resultado de la consulta, debe incluirse la tabla course en la cláusula FROM y la condición de coincidencia adicional en la cláusula WHERE.
-- course_id y nombres de cursos impartidos por cada profesor, junto con la sección, semestre y año
SELECT name, course.course_id, title, sec_id, year, semester
FROM instructor, teaches, course
WHERE instructor.ID = teaches.ID AND teaches.course_id = course.course_id
ORDER BY name, course_id, sec_id, year, semester;
En general, cuando se incluyen varias relaciones en la cláusula FROM, el funcionamiento de una consulta SQL puede describirse en tres pasos:
Genera un producto cartesiano de las tablas listadas en la cláusula
FROM.Aplica las condiciones especificadas en la cláusula
WHEREal resultado del paso 1.Para cada fila presente en el resultado del paso 2, muestra las consultas especificadas en la cláusula
SELECT.
Es importante mencionar que aunque esta secuencia de pasos ayuda a entender cuál debería ser el resultado de una consulta SQL, no es la forma cómo debería ejecutarse. Una implementación real de SQL no ejecutaría la consulta de esta manera; en su lugar, optimizaría la evaluación generando (en la medida de lo posible) solo aquellos elementos del producto cartesiano que satisfacen los predicados de la cláusula WHERE, para así procesar menos datos.
Al escribir consultas como las anteriores, se debe tener cuidado de incluir las condiciones adecuadas en la cláusula WHERE. Si se omiten, se producirá un producto cartesiano, el cual podría contener muchos registros.
Operaciones JOIN#
Los ejemplos de consultas en múltiples tablas que se han estudiado hasta el momento están basados en el producto cartesiano. Seguidamente, se introducen varias operaciones de JOIN (unión o cruce de datos) que permiten al programador escribir algunas consultas de una manera más natural y también formular consultas que son difíciles de implementar solamente con el producto cartesiano.
El estándar ANSI del SQL especifica cinco operaciones JOIN, las cuales actúan sobre dos tablas (izquierda y derecha) y producen otra tabla como resultado:
(INNER) JOIN: retorna los registros con valores coincidentes en ambas tablas.LEFT (OUTER) JOIN: retorna todos los registros de la tabla de la izquierda y los registros coincidentes de la tabla de la derecha.RIGHT (OUTER) JOIN: retorna todos los registros de la tabla de la derecha y los registros coincidentes de la tabla de la izquierda.FULL (OUTER) JOIN: retorna todos los registros de ambas tablas, tanto los que tienen valores coincidentes como los que no.CROSS JOIN: retorna el producto cartesiano de las dos tablas.
Los diferentes tipos de JOIN se representan como diagramas de Venn en la Fig. 6.
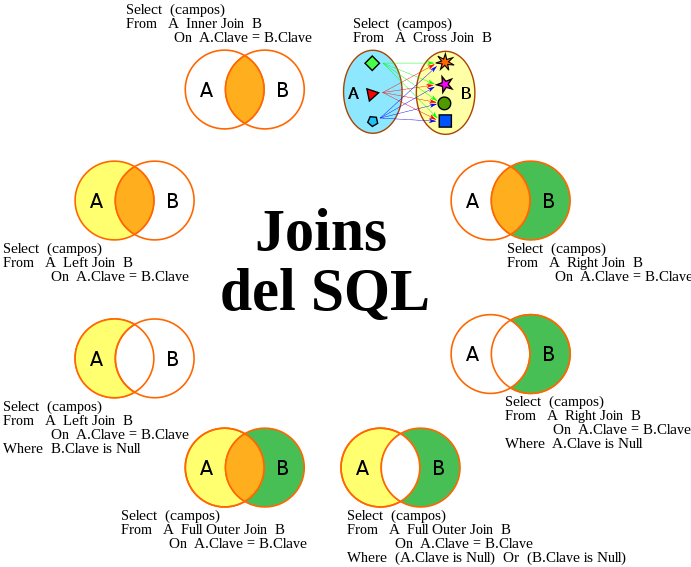
Fig. 6 Tipos de JOIN de SQL y sus representaciones como diagramas de Venn. Imagen compartida a través de Wikipedia.#
{kind=link}
A pesar de que los JOIN se definen para dos tablas, las operaciones pueden generarlizarse para involucrar más tablas.
La sintaxis general de una cláusula JOIN en una sentencia SELECT es la siguiente:
-- Sintaxis general de una cláusula JOIN
SELECT columna1, columna2, ...
FROM tabla_izquierda
INNER|LEFT|RIGHT|FULL|CROSS JOIN tabla_derecha ON condición
La cláusula ON define la condición de coincidencia sobre la cual se basa la operación JOIN (ya sea INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL JOIN o CROSS JOIN) que se está realizando. Especifica cuáles columnas de las tablas que se están uniendo deben compararse y cómo deben compararse. Solo las filas que satisfacen esta condición de coincidencia se incluyen en el resultado.
Seguidamente, se describen en detalle los diferentes tipos de JOIN.
INNER JOIN#
Un INNER JOIN, también conocido simplemente como JOIN, retorna solo las filas que tienen valores coincidentes en ambas tablas.
Por ejemplo, la siguiente consulta utiliza un INNER JOIN para unir datos de las tablas student y takes con base en la coincidencia de los valores de la columna ID en student y la columna ID en takes.
-- ID y nombres de estudiantes, junto con los id de los cursos matriculados
-- (con INNER JOIN explícito)
SELECT student.ID, name, course_id
FROM student
INNER JOIN takes ON student.ID = takes.ID;
El mismo resultado puede obtenerse listando ambas tablas en la cláusula FROM y reaizando un producto cartesiano, como se mencionó anteriormente. A esta operación se le conoce como INNER JOIN “implícito”.
-- ID y nombres de estudiantes, junto con los id de los cursos matriculados
-- (INNER JOIN implícito)
SELECT student.ID, name, course_id
FROM student, takes
WHERE student.ID = takes.ID;
Si se desea, por ejemplo, agregar el nombre de cada curso a la consulta anterior, puede hacerse con un INNER JOIN adicional a la tabla course.
-- ID y nombres de estudiantes, junto con los id y nombres de los cursos matriculados
SELECT student.ID, name, course.course_id, title
FROM student
INNER JOIN takes ON student.ID = takes.ID
INNER JOIN course ON takes.course_id = course.course_id;
Ejercicios#
Escriba consultas en SQL para obtener, de la base de datos university:
ID y nombre de estudiantes que han matriculado cursos en el año 2023.
ID y nombre de estudiantes que han matriculado cursos en el año 2023, junto con el promedio de esos cursos para cada estudiante.
LEFT JOIN#
Un LEFT JOIN, también conocido como LEFT OUTER JOIN, retorna todas las filas de la tabla de la izquierda y las filas coincidentes de la tabla de la derecha. Si no hay una coincidencia para una fila particular de la tabla de la izquierda, los valores para las columnas de la tabla de la derecha serán NULL. La operación LEFT JOIN garantiza que todas las filas de la tabla de la izquierda estén presentes en el resultado, independientemente de si hay o no una coincidencia en la tabla de la derecha.
Por ejemplo, retomemos la consulta sobre los cursos impartidos por cada profesor, junto con la sección, año y semestre correspondientes. Sabemos que puede implementarse con INNER JOIN.
-- course_id de cursos impartidos por cada profesor, junto con la sección, semestre y año
SELECT name, course_id, sec_id, year, semester
FROM instructor
INNER JOIN teaches ON instructor.ID = teaches.ID
ORDER BY name, course_id, sec_id, year, semester;
Sin embargo, el resultado de esta consulta no incluye profesores registrados en instructor que no tengan cursos en teaches. Esto podría lograrse con LEFT JOIN.
-- course_id de cursos impartidos por cada profesor, junto con la sección, semestre y año, incluyendo profesores que no hayan impartido cursos
SELECT name, course_id, sec_id, year, semester
FROM instructor
LEFT JOIN teaches ON instructor.ID = teaches.ID
ORDER BY name, course_id, sec_id, year, semester;
Nótese que las columnas course_id, sec_id, year y semester tienen NULL en los registros de profesores que no han impartido ningún curso. Esto puede aprovecharse para encontrar específicamente los profesores que no han impartido ningún curso: mediante una condición en la cláusula WHERE se seleccionan los registros donde alguna columna de la tabla de la derecha es NULL.
-- Profesores que no han impartido ningún curso
SELECT instructor.ID, instructor.name
FROM instructor
LEFT JOIN teaches ON instructor.ID = teaches.ID
WHERE teaches.ID IS NULL;
Ejercicios#
Escriba consultas en SQL para obtener, de la base de datos university:
Para cada estudiante, un registro por curso matriculado, sección, año, semestre y nota. Cada registro deben tener tanto el ID como el nombre del estudiante. Esta lista debe incluir los estudiantes en la tabla
student.ID y nombre de todos los estudiantes con su promedio general (de todos los cursos que hayan matriculado). La lista debe incluir a todos los estudiantes en
student.ID y nombre de todos los estudiantes que no han matriculado ningún curso.
RIGHT JOIN#
Un RIGHT JOIN, también conocido como RIGHT OUTER JOIN, retorna todas las filas de la tabla de la derecha y las filas coincidentes de la tabla de la izquierda. Si no hay una coincidencia para una fila particular de la tabla de la derecha, los valores para las columnas de la tabla de la izquierda serán NULL. La operación RIGHT JOIN garantiza que todas las filas de la tabla de la derecha estén presentes en el resultado, independientemente de si hay o no una coincidencia en la tabla de la izquierda.
Por ejemplo, la consulta sobre los cursos impartidos por cada profesor, junto con la sección, año y semestre correspondientes, incluyendo profesores registrados en instructor que no tengan cursos en teaches, y que anteriormente se resolvió con LEFT JOIN, también puede resolverse con RIGHT JOIN.
-- course_id de cursos impartidos por cada profesor, junto con la sección, semestre y año, incluyendo profesores que no hayan impartido cursos
SELECT name, course_id, sec_id, year, semester
FROM teaches
RIGHT JOIN instructor ON teaches.ID = instructor.ID
ORDER BY name, course_id, sec_id, year, semester;
En la práctica, muchas veces las consultas que utilizan RIGHT JOIN pueden ser reescritas para usar LEFT JOIN, y viceversa, simplemente cambiando el orden de las tablas. Sin embargo, en ciertos contextos y para ciertas lógicas de consulta, una de las opciones puede ser mejor que la otra.
FULL JOIN#
Un FULL JOIN, también conocido como FULL OUTER JOIN, retorna todas las filas de ambas tablas, tanto las que tienen valores coincidentes como las que no. Si hay una coincidencia entre las filas de las tablas basada en la condición especificada, esas filas se combinarán en el resultado. Si no hay una coincidencia para una fila particular en una de las tablas, los valores para las columnas de la otra tabla serán NULL.
En otras palabras, un FULL JOIN combina las características del LEFT JOIN y del RIGHT JOIN. Devuelve todas las filas de la tabla de la izquierda que tienen coincidencias en la tabla de la derecha, todas las filas de la tabla de la derecha que tienen coincidencias en la tabla de la izquierda, y todas las filas de ambas tablas que no tienen coincidencias entre sí.
Supongamos que se desea obtener una lista de todos los estudiantes y todos los cursos que han tomado, incluyendo a los estudiantes que no han tomado ningún curso y los cursos que no han sido tomados por ningún estudiante.
-- Lista de todos los estudiantes y todos los cursos que han tomado,
-- incluyendo a los estudiantes que no han tomado ningún curso
-- y los cursos que no han sido tomados por ningún estudiante
SELECT student.ID, student.name, takes.course_id, takes.grade
FROM student
FULL JOIN takes ON student.ID = takes.ID;
El FULL JOIN es útil cuando se desea conservar todas las filas de ambas tablas en el conjunto de resultados, independientemente de si hay coincidencias. Sin embargo, es menos común que los otros tipos de JOIN y no es soportado por todos los SABD.
CROSS JOIN#
La operación CROSS JOIN retorna el producto cartesiano de dos tablas. Es decir, combina cada fila de la primera tabla con cada fila de la segunda tabla. No necesita una condición de coincidencia, como es el caso con otros tipos de JOIN.
El resultado de un CROSS JOIN es una tabla con número de filas igual al producto del número de filas de las dos tablas involucradas. Por ejemplo, si una tabla tiene 5 filas y la otra tiene 3, el resultado del CROSS JOIN tendrá 15 filas.
Por ejemplo, la siguiente consulta retorna todas las combinaciones posibles de profesores y estudiantes. En el resultado, cada profesor se asocia con cada estudiante.
-- Producto cartesiano de instructor y student
SELECT instructor.ID AS instructor_ID, instructor.name AS instructor_name,
student.ID AS student_ID, student.name AS student_name
FROM instructor
CROSS JOIN student
ORDER BY instructor_ID, instructor_name, student_ID, student_name;
El uso de CROSS JOIN podría ser menos común que otros tipos de JOIN, ya que generalmente se busca combinar datos basados en alguna condición lógica. Sin embargo, hay situaciones, especialmente en análisis de datos o generación de conjuntos de datos específicos, en los que CROSS JOIN puede ser útil.
Ejercicios#
El script idea-cibernetica.sql contiene varios comandos SQL para crear las tablas y cargar datos en la base de datos de personal de la compañía de desarrollo de software “Idea Cibernética S.A.”.
Estudie el script
idea-cibernetica.sqly observe la estructura de las tablas, las relaciones entre estas, sus tipos de datos y restricciones. Preste atención a:El (pseudo) tipo de datos serial. Es uno de los mecanismos disponibles en SQL para autoincrementar el valor de una columna y así evitar repeticiones. Estas columnas pueden utilizarse como llaves primarias.
El tipo de datos date.
Cree una base de datos (ej.
idea-cibernetica) en PostgreSQL y ejecuteidea-cibernetica.sql.Liste el nombre, los apellidos y el nombre del departamento de cada empleado.
Liste el nombre, los apellidos, el nombre del departamento y el nombre del puesto de cada empleado.
Calcule y liste la edad de cada uno de los empleados, al 2023-09-21, con base en la fecha de nacimiento. Sugerencia: utilice las funciones AGE() y DATE_PART(). Ejemplo:
-- Edad de los empleados al 2023-09-21
SELECT
nombre,
apellidos,
fecha_nacimiento,
DATE_PART('year', AGE('2023-09-21', fecha_nacimiento)) AS edad
FROM empleado;
Calcule y despliegue la edad promedio de todos los empleados.
Calcule y despliegue la edad promedio de los empleados de cada departamento. Muestre el nombre del departamento.
Liste los departamentos que no tienen empleados.
Calcule y despliegue el salario promedio de todos los empleados.
Calcule y despliegue el salario promedio de los empleados de cada departamento. Muestre el nombre del departamento.
Liste los empleados que no están asignados a ningún proyecto.
Liste los proyectos que no tienen empleados asignados.
Liste los proyectos que no han concluído al 2023-09-21.
Encuentre el proyecto con el mayor período de ejecución.
Operaciones de conjuntos#
SQL implementa las operaciones unión de conjuntos, intersección de conjuntos y diferencia de conjuntos.
Todas las operaciones de conjuntos actúan en los resultados de dos sentencias SELECT, los cuales deben cumplir con las siguientes condiciones:
Deben tener el mismo número de columnas.
Los tipos de datos de las columnas deben coincidir.
El orden de las columnas también debe coincidir.
Sintaxis básica
-- Sintaxis básica de las operaciones de conjuntos
SELECT columna1, columna2, ...
FROM tabla1
UNION|INTERSECT|EXCEPT
SELECT columnna1, columna2, ...
FROM tabla2;
Unión#
La operación UNION une los resultados de dos sentencias SELECT.
Ejemplo:
-- Unión de los cursos del semestre S1 de 2022 y S1 de 2023
SELECT course_id
FROM section
WHERE semester = 'S1' AND year = 2022
UNION
SELECT course_id
FROM section
WHERE semester = 'S1' AND year = 2023;
UNION elimina automáticamente los duplicados (al igual que la operación de conjuntos en la que está basada), por lo que la consulta anterior no retorna valores repetidos de course_id. Por este motivo, UNION se utiliza con frecuencia precisamente para eliminar duplicados. Si se desea conservar los valores duplicados, puede utilizarse la variante UNION ALL.
-- Unión de los cursos del semestre S1 de 2022 y S1 de 2023,
-- incluyendo valores duplicados
SELECT course_id
FROM section
WHERE semester = 'S1' AND year = 2022
UNION ALL
SELECT course_id
FROM section
WHERE semester = 'S1' AND year = 2023;
Intersección#
La operación INTERSECTS retorna los valores en común de dos sentencias SELECT.
Ejemplo:
-- Intersección de los cursos del semestre S1 de 2022 y S1 de 2023
SELECT course_id
FROM section
WHERE semester = 'S1' AND year = 2022
INTERSECT
SELECT course_id
FROM section
WHERE semester = 'S1' AND year = 2023;
La consulta anterior retorna los course_id de los cursos impartidos en ambos semestres.
Diferencia#
La operación EXCEPT retorna los valores presentes en un conjunto de datos, pero no en el otro.
Ejemplo:
-- Cursos impartidos en el semestre S1 de 2022, pero no en el S1 de 2023
SELECT course_id
FROM section
WHERE semester = 'S1' AND year = 2022
EXCEPT
SELECT course_id
FROM section
WHERE semester = 'S1' AND year = 2023;
Al igual que UNION, EXCEPT no retorna valores duplicados. Si se desea conservarlos, puede utilizarse la variante EXCEPT ALL.
-- Cursos impartidos en el semestre S1 de 2022, pero no en el S1 de 2023,
-- incluyendo valores duplicados.
SELECT course_id
FROM section
WHERE semester = 'S1' AND year = 2022
EXCEPT ALL
SELECT course_id
FROM section
WHERE semester = 'S1' AND year = 2023;
Recursos de interés#
Bibliografía#
- 1
En la representación de punto fijo, la posición del punto decimal es fija y no cambia. Por ejemplo, si se tiene un sistema de punto fijo de 4 dígitos con 2 posiciones después del punto decimal, el número 123.45 se representaría como 12345 y se entendería que el punto decimal está entre el segundo y tercer dígito desde la derecha. Generalmente, las operaciones de punto fijo son más rápidas y consumen menos recursos del hardware en comparación con las operaciones de punto flotante, especialmente en hardware que no tiene soporte dedicado para operaciones de punto flotante.
- 2
En la representación de punto flotante, la posición del punto decimal puede variar, y el número se representa en términos de una mantisa y un exponente. Por ejemplo, el número 123.45 podría representarse como 1.2345 × 102 (1.2345 es la mantisa y 2 el exponente). Requiere hardware más complejo para realizar operaciones, pero esto se ha vuelto menos problemático con el tiempo, debido a la inclusión de unidades de punto flotante (FPU) en la mayoría de los procesadores modernos.